������Դ������Ԫ

����������Ԫ������ͼ�齱��������Ҷ˹����֮��Judea Pearl��ǰ��arXiv�ϴ��������������ģ�������ǰ����ѧϰ���۾��ޣ��������������������7��������Pearlָ������ǰ�Ļ���ѧϰϵͳ������ȫ��ͳ��ѧ��äģ�͵ķ�ʽ���У�������ΪǿAI�Ļ���������Ϊͻ�ƿ����ڡ����������������ṹ���������ģ�ͣ��ܶ��Զ��������������ع��ס�
�������ѧϰ�����о��Ѿ�������Խ��Խ��Ĺ�ע�����ǣ�����ѧϰҲ���������ϵľ����ԡ�
����Ȼ���������������Ĺ�ע���ƺ���û������������
�������գ�ͼ�齱��������Ҷ˹����֮��Judea Pearl��arXiv�ϴ��������������ģ�������ǰ����ѧϰ���۾��ޣ��������������������7��������
�����������㻹�ǵ� NIPS 2017��Judea Pearl ��į����Ӱ�D�D�������ڻ���ѧϰ���۾��ı�����ϣ�����������ϡ�١�

CMU����Eric Xing����Ϣ��Judea Pearl����᳡�˼�ϡ�٣�ͼƬ������־��
�����������Ŀ������ѧϰ�������ϰ�����Theoretical impediments to machine learning��������Judea Pearl�Ի���ѧϰ���ر������ѧϰ�������۵�˼����
������Ȼ�����ֳ��������ǿ���ϸϸ�Ķ�Pearl��ƪ����������������ġ�
����Judea Pearl����į����Ӱ�����������δ�����7���
����Judea Pearl �����2011���ͼ�齱�����������˹���������Ļ����Թ��ף���������ʺ�������������㷨�����ı����˹�����������ڹ�������ķ�������Ҫ���о������Ǹ���ͼģ�ͺ�������������ǻ���ѧϰ�Ļ������⡣ͼ�齱ͨ����������ۼ����ѧ�ߣ��������ڽ���������ܹ����ܵ�ѧ�ߡ�
������Ϊ UCLA �������ѧϵ�Ľ��ڣ�Judea Pearl�����ξ��ڿ�ѧ���������ģ���һ������ 20 ���� 80 �������Ϊ�˹�����������һ���µĹ��ߣ��б�Ҷ˹���硣�ڶ��θ��������ڱ�Ҷ˹�����ڼ����ϵ����ƣ�Pearl ��ʶ����ͼģ�ͺ����ۣ����籴Ҷ˹�����е�������Ҳ�����������ϵ����������һ����Ϊ�˹����ܵķ�չ�춨����һ��������������Զ����ˣ���һ����֤�����ϵ�ġ������Ե���ѧ�����������Ѿ������п�ѧ������ѧ������á�
����Judea Pearl �����������ҹ���ԺԺʿ��AAAI �� IEEE Fellow���������������������� Daniel Pearl ��������ϯ�����Ķ���Daniel Pearl���ǻ������ձ����ߣ�2002�걻�ͻ�˹̹�ֲ����Ӱ�ܲ�ն�ף�Ϊ����������ר������һ����Ӱ �� A Mighty Heart�� ����
��������ѧϰ�����ϰ�����������ߴ��

����ժҪ
����Ŀǰ�Ļ���ѧϰϵͳ������ȫ��ͳ��ѧ��äģ�͵ķ�ʽ���У������������������������ϸ�������ϵ����ơ�������ϵͳ����������Ԥ�ͷ�˼����˲�����ΪǿAI�Ļ�����Ϊ�˴ﵽ��������ˮƽ����ѧϰ�Ļ�����Ҫ��ʵģ�͵�ָ�������������������������ʹ�õ�ģ�͡�Ϊ����ʾ��Щģ�͵���Ҫ���ã��ҽ�����߸�������ܽᣬ��Щ�����ǵ�ǰ����ѧϰϵͳ��ʵ�ֵģ�������ʹ�������ģ������ɵġ�
������ѧ����
��������������������������ѧϰ��ϵͳ�����Ƿ�����������ȫ��ͳ��ѧ�ķ�ʽ���С����仰˵��ѧϰ����ͨ�����Ի����ĸй��������������Ż������ܡ�����һ�������Ĺ��̣��ںܶ�������ڴ���Ľ����۵���Ȼѡ����̡�
��������������ӥ����������������������������ʱ���չ���߳����Ӿ�ϵͳ��Ȼ���������ܽ��ͿƼ����������Ĺ��̣����������ܹ��ڼ�ǧ���ʱ���ィ���۾�����Զ����
����������ӵ�ж�����������ȱ������һ������������һ���������������־�������衢�滮��ѧϰ������������ͼ��������������N. Harari������ɭ��S. Mithen������������ѧ���ձ���ͬ��һ�㡣
������4����ǰ��������������ʵ��ȫ��ͳ�εľ��������أ������DZ��Ż������������������������ɱ�����̬�ȡ���ͨ������ľ������ж��������衰����������أ����������������̽����������Ҳ�ȡ�ж��أ����Լ��ع��ԡ������Է�˼��������Ҳ�ȡ�˲�ͬ���ж��أ�������������ǽ�ֹ���̻��������� ������������ѧϰ�����߱������Щ�����������
��������Ϊ�����Щ����Ĺؼ��Ǹ�����װ�������������������ѧϰ���Դﵽ������֪ˮƽ�����������20��ǰ�ķ���ʵ��Ϣ��ѧ���ξ��Ѿ����Ʋ��ˣ������첻��������
����ͼ�κͽṹģ�͵Ľ���ʹ����ʵ���������ڹ������Ӷ�ʹ��ģ������������һ������ǰ;�ķ������ڽ���ǿ���AI������һ���У��ҽ�ʹ�������������������ѧϰϵͳ�����ٵ��ϰ������������ι�����������е����������һ���ܽ�����������ִ�����ƶϹ��߹����Щ�ϰ���
���������ϵ��������
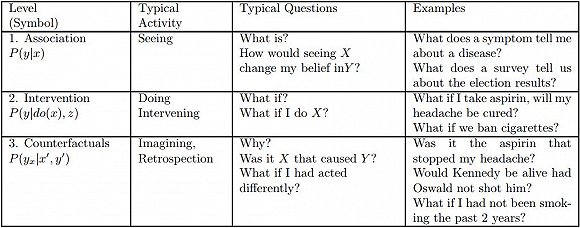
ͼ1�������ϵ�㼶��i ��������ֻ���� i �������ϼ������Ϣ�ܹ���ȡʱ���ܱ��ش�
�������������������ʾ��һ���dz����õļ����ǣ���ÿ������ܹ��ش���������Ͷ��ԣ����ڶ������Ϣ��һ�������ķ��ࡣ
������������γ���һ������IJ�νṹ������ζ��ֻ�е���� j��j �� i������Ϣ���Ի��ʱ����� i��i = 1,2,3���ϵ�������ܱ��ش�
����ͼ1��ʾ����3���IJ�νṹ���Լ�ÿ��������Իش�ĵ������⡣��Щ����ֱ�Ϊ�������루Association�����ڸ�Ԥ��Intervention�����۷���ʵ��Counterfactual����ѡ����Щ������Ϊ��ǿ�����ǵ��÷������ǽе�һ�����룬��Ϊ�������˴����ͳ�ƹ�ϵ���������ݶ��塣���磬��������Ĺ˿�Ҳ�����������ߣ����ֹ�������ʹ����������ֱ�Ӵӹ۲��������ƶϳ�������һ����������ڲ���Ҫ�����Ϣ����˱���������ײ㡣�ڶ�����Ԥ������Ҫ�ߣ���Ϊ���漰�IJ������ǿ���ʲô���������ı������������ġ��������ĵ��������ǣ�������ǽ��۸�ӱ��ᷢ��ʲô�����������ⲻ�ܵ��������������ش���Ϊ�����漰���ͻ���Ϊ�ı仯�����Ӱ���µĶ��ۡ���Щѡ���������ǰ���Ǽ�����кܴ�ͬ�����������Ǿ�ȷ�ظ��Ƽ۸�ﵽĿǰ��ֵ�������г��������������㱻��Ϊ����ʵ��Ϣ��Counterfactuals���������������ݵ���ѧ�Ҵ���?���Ӻ�Լ��?˹ͼ����?���գ�John Stewart Mill����Ҳ�ǹ�ȥ��ʮ����һֱʹ�õģ��Լ�����Ѻõ����塣����ʵ����е�һ�����������ǣ�������Ҳ�ȡ�˲�ͬ���ж�����ô�족�������Ҫ��������
��������ʵ�����ڲ�νṹ����㣬����Ϊ���ǰ�����Ԥ����������⡣���������һ�����Իش���ʵ�����ģ�ͣ�����Ҳ�����������ش���ڸ�Ԥ����������⡣���磬����Ѽ۸�ӱ��ᷢ��ʲô����Ԥ�����⣩����ͨ�����һ������ʵ���������ش𣺼۸���Ŀǰ��ֵ�������ᷢ��ʲô��ͬ���������ǿ��Իش��Ԥ�����⣬����������Ҳ�ܵõ��ش�
�����෴��������������ģ�ͣ������ܻش���ϲ�����⣬�������Dz��ܶ���Щ���ܹ�ҩ�����Ƶ����������½���ʵ�飬��������û�г�ҩ�Ļ��л���������Ϊ����ˣ���νṹ���з����Եģ���������ǿ��IJ�Ρ�
��������ʵ�ǿ�ѧ˼ά�Ļ�ʯ�����ɺ͵����������ǡ����磬�����·�ͥ�����汻��Ϊ������˺���������ס����û�б������Ϊ���˺��ܿ��ܾͲ��ᷢ���������û�С��ļ�������Ҫ��Ƚ���ʵ�����û�з���������Ϊ����һ�����硣
������νṹ�е�ÿһ�㶼��һ���䷨ǩ��������������¼����Dz���䡣���磬��������������������ʾ䣬����P��y | x��= p��˵�����������ǹ۲쵽�¼�X = x���¼�Y = y�ĸ��ʵ���p���ڴ���ϵͳ�У�����ʹ�ñ�Ҷ˹������κ�֧�����ѧϰϵͳ������������Ч������Щ֤�ݾ��ӡ�
�����ڽ���㣬�����ҵ�����ΪP��y | do��x����z���ľ��ӣ�����ʾ���¼�Y = y�ĸ��ʣ��������ǽ��벢��X��ֵ��Ϊx��Ȼ��۲��¼�Z = �������ı���ʽ���Դ�����������ʹ�������Ҷ˹���磨Pearl��2000����3�£�����ʵ���ԵĹ��ơ�һ������ͨ���Ի�������Ȥ���ݣ�ͨ����һ��ȷ���ԵIJٳ��ϣ���ѧϰ��Ԥ��Ч�����˹����ܹ滮��Աͨ����ʹ����ָ������Ϊ����ø�Ԥ֪ʶ�����������ж�����ܴӱ����۲����ƶϸ�����
��������ڷ���ʵ�����ϣ�������������P��yx | x"��y"���ı���ʽ����������������ǹ۲쵽X��x���¼�Y = y�ĸ��ʾͻᱻ�۲쵽����������ʵ���Ϲ۲쵽X��x����Y��y"�����磬���Joe�����ѧ�����Ĺ��ʾͻ���y��������ֻ���������ѧ����ʵ�ʹ��ʾͻ���y������ֻ��������ӵ�й��ܻ�ṹ����ģ��ʱ�������Щģ�͵�����ʱ�����ܼ�����������ľ��ӡ���Pearl��2000����7�£���
���������νṹ�����������ʽ���ƣ�������Ϊʲô����ͳ��ѧ�Ļ���ѧϰϵͳ�������ж���ʵ��ͽ��͡���Ҳ����������Ҫ��Щ�����ͳ����Ϣ���Ժ��ָ�ʽ��֧����Щ����ģʽ��
�����о���Ա�����е����ȵ��ǣ������νṹ�����˰����ѧϰ�ijɾͽ���������ļ�����α����������ϰ���С�һ���������ֱȽϵĹ۵���Ϊ�������ѧϰ�����Ǿ������١�����ϡ�����������ϵ�Ŀ���Ǿ����������ϡ������ҵ��ǣ��ָ�����������ϰ��ڲ�νṹ�и������ǣ����ǵ�Ŀ�꺯�������ʲ�����Ҫ��ֻҪ���ǵ�ϵͳ�Ż��۲����ݵ�ijЩ���ԣ���û���ἰ����֮������磬�����ֻص��˲�νṹ�ĵ�һ���棬��һ��������������ԡ�
�����������ģ�͵�7��֧�����������������ģ����ʲô��
������������ 5 �����⣺
�����������Ʒ�������ij�ּ������ж���Ч��
�������µ�˰���Żݵ�����������������
����ÿ���ҽ�Ʒ������������ڷ���֢�������ർ�µ���
������Ƹ��¼����֤���������Ա���������
������Ӧ�÷����ҵĹ�����
������Щ�����һ�����������ǹ��ĵĶ���ԭ���ЧӦ�Ĺ�ϵ������ͨ�����絼�¡����ڡ�֤����Ӧ�õȴʿ��������ϵ����Щ�����ճ������кܳ������������һֱ����Ҫ��Щ����Ĵ𰸡�Ȼ����ֱ�������û���㹻�õĿ�ѧ��������Щ������б��������˵�ش���Щ�����ˡ��ͼ���ѧ����еѧ����ѧ������۵Ĺ��ɲ�ͬ��ԭ���ЧӦ�Ĺ���������Ϊ���ʺ�Ӧ����ѧ�������з�����
�������ǣ���ȥ30�����������ѷ�����仯��һ��ǿ���������ѧ�����ѱ������������ڴ��������ϵ���������İ��������ת��Ϊ��ѧ���ĵĹ��ߡ���Щ�����������ܹ�����������⣬Ȼ�������������ƴ𰸡�
�����Ұ�����ת����Ϊ�������������Pearl and Mackenzie, 2018, forthcoming���������������������������ҽ����֮Ϊ���ṹ�����ģ�͡���Structural Causal Models��SCM����
����SCM �������ֹ��ɣ�ͼģ�͡��ṹ�����̡�����ʵ��Ԥʽ��
�������У�ͼģ����Ϊ����֪ʶ�����ԣ�����ʵ�������������⣬�ṹ�����������������彫ǰ���߹���������
�����������ҽ����� SCM ��ܵ� 7 ������Ҫ�����ԣ�������ÿ�����Զ��Զ������������Ķ��ع��ס�
����1. �����������D�D���ȺͿɲ�����
����һ����������Դ����ȣ�transparency���Ϳɲ����ԣ�testability����Ҫ����һ�ֽ��յġ����õ���ʽ����������������һ�������顣����ʹ������Ա�ܹ����������ļ����Ƿ���������ڿ�ѧ���ݣ��������Ƿ��б�Ҫ���ж���ļ��衣�ɲ������������ǣ������Ƿ���ʦ���ǻ������ܹ�ȷ��������ļ����Ƿ���������ݼ��ݣ���������ݣ���ʶ����Щ��Ҫ���ļ��衣
����ͼģ�ͣ�graphical models���Ľ���ʹ���ձ����ÿ��С����ǵ�������Դ������һ����ʵ�����м��趼����ͼ�α���ģ������о���Ա�������������ϵ�����ⷽʽ��һ�µģ�����Ҫ�Է���ʵ��ͳ�������Ե��жϣ���Ϊ��Щ���Դ�ͼ�Ľṹ�ж������ɲ�������ͨ��һ����Ϊd-separation��ͼ�α����ٽ��ģ����ṩ��ԭ�����֮��Ļ�����ϵ�����������ǣ�����ģ�����κθ�����·��ģʽ����Щ����ģʽ��������Ӧ�ô��ڵģ�Pearl, 1988����
����2. Do-calculus�Ϳ��ƻ���
�������ӣ�confounding��������˵������������������δ���۲쵽�����أ�������������Ϊ�Ǵ������еó�����ƶϵ���Ҫ�ϰ���ͨ��һ�ֳ�Ϊ��back-door����ͼ�α����ԡ�����ӡ���deconfound����ѡ��һ����ʵı��������ƻ��ӵ������Ѿ�����һ���ġ�roadblocks�����⣬������һ�����㷨�����Pearl, 1993����
����������Щ��back-door������������ģ�ͣ���һ���������������do-calculus��������Ԥ���κο�������²��Ը�Ԥ��Ч������Ԥ�ⲻ�����ض��ļ�����ȷ��ʱ������ʧ���˳���Pearl, 1995; Tian and Pearl, 2002; Shpitser and Pearl, 2008����
����3. ����ʵ���㷨��
��������ʵ�������������ض��������Ϊ������һ�鲻ͬ��������ȷ�������磬����Joe��н��ΪY = y������������X = x���ѧ����ôJoe��н���Ƕ����أ���ô����Joe����һ���ѧ������н�ʻ��Ƕ��٣�
�������������һ��ɾ��ǣ���ͼ�α�ʾ�н�����ʵ������ʽ����ͼ�α�ʾ���о���Ա���������ѧ֪ʶ��һ�ֱ�����ʽ��ÿ���ṹ����ģ�Ͷ�������ÿ������ʵ������ֵ����ˣ����ǿ���ͨ���������жϾ��ӵĸ����Ƿ����ͨ��ʵ���۲��о���ȷ������ͨ�������ߵ����������[Balke and Pearl, 1994; Pearl, 2000, Chapter 7]��
�������й�����������У������ر����Ȥ���ǹ��ڡ�Ч����ԭ��causes of effects���ķ���ʵ���⣨�͡�ԭ���Ч������ԣ������磬Joeȥ��Ӿ��Joe�����ı�Ҫ�����֣�ԭ��Pearl, 2015a; Halpern and Pearl, 2005����
����4. ���������ֱ�ӡ����ЧӦ������
�������������mediation analysis����ע���ǽ��仯��ԭ�ݵ�Ч���Ļ��ơ����м���Ƶļ�������ɽ��͵Ļ������ұ���Ӧ�÷���ʵ���������м�⡣����ʵ��ͼ�α�ʾʹ�����ܹ�����ֱ�Ӻͼ��ЧӦ����ȷ����ЩЧӦ���Դ����ݻ�ʵ����Ƶ�������Robins and Greenland, 1992; Pearl, 2001; VanderWeele, 2015����������������Իش�ĵ��������ǣ�X��Y��Ӱ���ж������ɱ���Z���µġ�
����5. �ⲿ��Ч�Ժ�����ѡ��ƫ��
��������ʵ���о�����Ч�Զ��ܵ�ʵ���ʵ������֮������Ӱ�졣���������������仯ʱ������û���ڴ���ij��������ѵ���Ļ������ܹ��������ã�������Щ�仯�Ǿֲ��ġ���ȷ���ġ�������⼰����ֱ�����ʽ���Ѿ�������ѧϰ�о����Ͽɣ����硰������Ӧ������Ǩ��ѧϰ����������ѧϰ���͡��ɽ��͵��˹����ܡ��ȵȣ���Щֻ���о���Ա�����������о���һЩ��������ͼ�����Ƚ��ԣ�robustness�����ձ����⡣
�������ҵ��ǣ��Ƚ��Ե�������Ҫ���������ģ�ͣ����Ҳ����ڹ��������Ͻ��д���������������ϣ���������ȴ�ʩ���Ѿ����Թ��ˡ�������association��������ȷ���������ı仯��Ӱ��Ļ��ơ�����ǰ�����۵� do-calculusΪ�˷������仯������ƫ���ṩ��һ�������ķ��������ȿ��������µ���ѧϰ�����Թ�ܻ����仯��Ҳ�����ڿ��Ʒǵ���������ƫ�Bareinboim and Pearl, 2016����
����6. ���ݶ�ʧ
�������ݶ�ʧ������������ʵ���ѧ��ÿһ��֧�����磬�ܷ���û�лش�ȫ�ʾ�������Ŀ���������������仯��ʧ�飬���߾�����Ϊδ֪��ԭ���˳��ٴ��о�������������⣬����������������ͳ�Ʒ�����äģ�ͷ�ʽ��model-blind paradigm������ˣ���Щ�о����ؾ��������ݶ�ʧ��������������Ҳ����˵����ģ��������������ֵ�ء�ʹ�ö�ʧ���̣�missingness process�������ģ�ͣ��������ڿ��������ϵ���ʹ�ϵ�Ӳ������������лָ�����������ֻҪ�������㣬�Ϳ��Եõ��������ϵ��һ�¹��ƣ�Mohan and Pearl, 2017����
����7. �������
����ǰ��������d-separation��ʹ�����ܹ������оٸ��������ģ�͵Ŀɲ����ƶϡ���Ϊ���ò���ȷ�ļ�������ݼ��ݵ�ģ�ͼ��Ͻ��������ṩ�˿��ܣ����ҿ��Խ��յر�ʾ������ϡ�ϵͳ�������Ѿ���������������ijЩ����£����Խ�һ�����ģ�͵ļ�����������ֱ�ӴӸü����������������ij̶ȣ�Spirtes et al., 2000; Pearl, 2000; Peters et al., 2017����
��������
������ѧ��Stephen Toulmin��Ϊ������ģ����äģ�͵Ķ��ַ�������ͱ������ϣ����ѧ֮�侺���Ĺؼ�������Toulmin��˵�����ͱ�������ѧ���Ǻ���Ԥ��ĸ��֣���ȷ�Ժ�һ���Է���ԶԶ�����˹�ϣ���ˣ�Toulmin��1961��pp.27-30����Ȼ����ѧȴ����ϣ������ѧ�ҵĴ�����˼��ս�ԣ�����ս�Ժ��ζ���ѧ������һ���ܿ�Ұ�����������Բ�ιܣ����Կ�������С�����������ڹ걳�ϵİ����ε���Ȼ�������ֿ�Ұ�Ľ�ģ���ԣ��߸���Eratosthenes����Ԫǰ276 - 194�꣩�ڹŴ��������д����Ե�ʵ��֮һ���������˵���İ뾶������Բ��ᷢ���ڰͱ��ס�
�����ص�ǿ�˹����ܣ������Ѿ��������Կ�ִ�е���֪������˵��äģ�͵ķ������������ơ��������������е�һЩ����չʾ�������SCM����������Щ�����Լ�����ִ����Щ����Ϊʲô����ģ�͵ķ����DZز����ٵġ����ǵ���������ǣ������AI���ܵ����ش�äģ�͵�ѧϰ�����г��֣�����Ҫ���ݺ�ģ�͵Ĺ���Э����
�������ݿ�ѧֻ������һ�ſ�ѧ���ѣ���Ϊ�������ڽ������ݣ�����һ�ֶ������⣬����������ʵ��ϵ���������������ж����α�����Ӧ�ã����ݱ���������һ�ſ�ѧ��
|

















